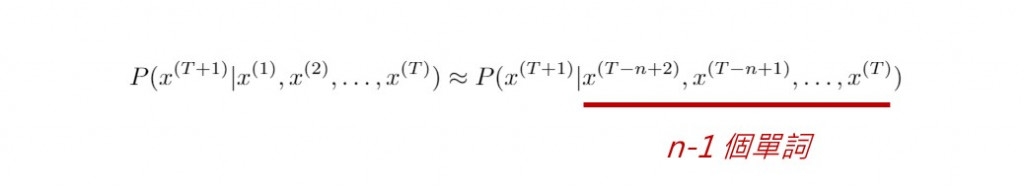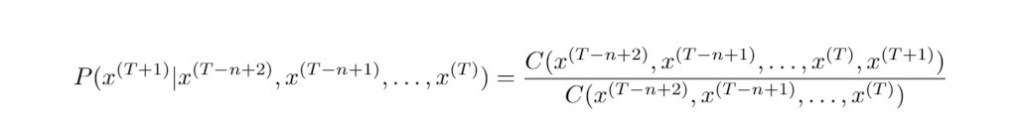上次我們提到,語言模型( language model, LM )就是賦予一段文句機率值。
在自然語言處理的許多情境中皆仰賴語言模型:

圖片來源:PhoneArena.com
名詞定義: n-gram 就是n個連續單詞構成的序列,例如 "store" 就是 1-gram、 "the store" 就是 2-gram、 "to the store" 就是 3-gram ,以此類推。
假設我們輸入 "Do you want to go to the" ,語言模型就會根據背後的演算法來預測下一個字將會是什麼?考慮一種可能的情況: "Do you want to go to the store" 。語言模型將會計算條件機率 P("store" | "Do you want to go to the") ,如下所示:
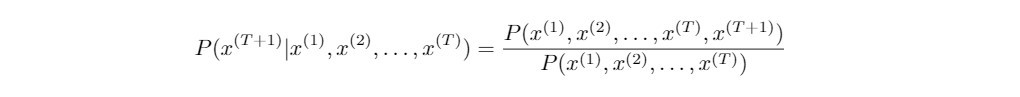
以我們的例子而言,*"Do", "you", ..., "the"*是已經給定的單詞序列,而待預測的下一個單詞 "store" 則須選自事先建立好的詞彙庫。上述的左式並不好實際計算,但是等號的右式則值得討論,因此理論上我們把語言模型轉化為估計以下T元詞組的機率值:
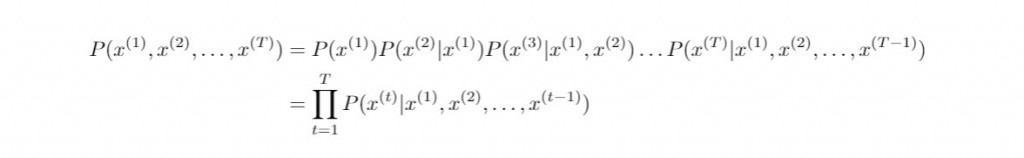
N元語法估計長度為 N 單詞之序列的機率測度,進而由 N-1 個已知的連續單詞序列( 歷史字串構成了 N-1 階馬可夫鏈 ),從而預測下一個出現的單詞。根據不同的參數 N ,我們可以整理出下列 N-gram 模型(N>4的情形以此類推):

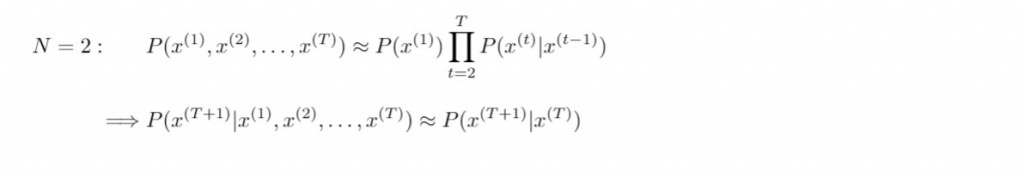
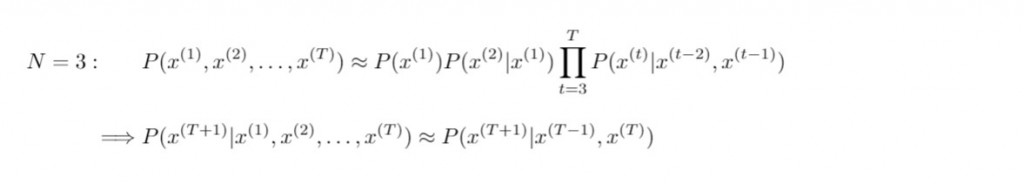
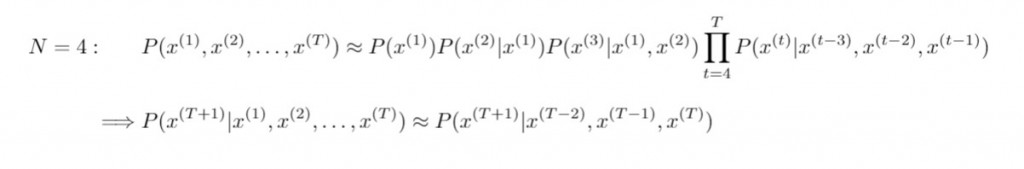
n-gram model 即是計算以下右側的條件機率:
昨天我們提到,右側的條件機率為n元詞組與(n-1)元詞組
出現的個數相除而得的比值,也一種相對頻率的概念。
相對頻率用來計算條件機率:
講了太多理論,想必早已令螢幕前的你昏昏欲睡吧!來點Python程式碼醒醒腦吧!
在正式利用 n-gram model 來預測關鍵字之前,我們先來計算文章中出現最多次的 n-grams 吧!和之前一樣,我們引用了BBC新聞 Facebook Under Fire Over Secret Teen Research 做為文本資料。
首先引入必要的模組以及在 NTLK 中已經定義好的函式 ngrams:
from collections import Counter
from nltk.util import ngrams
from preprocess_text import preprocess, clean_text # user-defined functions
接下來載入新聞全文當作原始資料並進行清理以及斷詞(不需要先進行斷句):
# Load the news article as raw text data
with open("bbc_news.txt", 'r') as f:
raw_news = f.read()
# Clean and tokenise raw text
tokenised = preprocess(clean_text(raw_news))
計算最高頻率的五個 1-grams :
# obtain all unigrams
news_unigrams = ngrams(tokenised, 1)
# count occurrences of each unigram
news_unigrams_freq = Counter(news_unigrams)
# review top 5 frequent unigrams in the news
print("Top 5 unigrams:\n{}".format(news_unigrams_freq.most_common(5)))
印出結果:
計算最高頻率的五個 2-grams :
# obtain all bigrams
news_bigrams = ngrams(tokenised, 2)
# count occurrences of each bigram
news_bigrams_freq = Counter(news_bigrams)
# review top 5 frequent bigrams in the news
print("Top 5 bigrams:\n{}".format(news_bigrams_freq.most_common(5)))
印出結果:
計算最高頻率的五個 3-grams :
# obtain all trigrams
news_trigrams = ngrams(tokenised, 3)
# count occurrences of each trigram
news_trigrams_freq = Counter(news_trigrams)
# review top 5 frequent trigrams in the news
print("Top 5 trigrams:\n{}".format(news_trigrams_freq.most_common(5)))
印出結果:
現在我們對於 n-grams 的相對頻率有一點感覺了,我們就用 n-gram model 預測關鍵下一個單詞的機制來寫一篇虛構的短文吧!
我們先利用 n-gram 為基礎定義一個馬可夫鏈文字生成器類別:
import nltk, re, random
from nltk.tokenize import word_tokenize
from collections import defaultdict, deque, Counter
import itertools
class MarkovChain:
def __init__(self, sequence_length = 3, seeded = False):
self.lookup_dict = defaultdict(list)
self.most_common = list()
self.seq_len = sequence_length
self._seeded = seeded
self.__seed_me()
def __seed_me(self, rand_seed = None):
if self._seeded is not True:
try:
if rand_seed is not None:
random.seed(rand_seed)
else:
random.seed()
self._seeded = True
except NotImplementedError:
self._seeded = False
def add_document(self, str):
"""
str: string of raw text data
"""
preprocessed_list = self._preprocess(str)
self.most_common = Counter(preprocessed_list).most_common(50)
pairs = self.__generate_tuple_keys(preprocessed_list)
for pair in pairs:
self.lookup_dict[pair[0]].append(pair[1])
def _preprocess(self, str):
cleaned = re.sub(r"\W+", ' ', str).lower()
tokenized = word_tokenize(cleaned)
return tokenized
def __generate_tuple_keys(self, data):
if len(data) < self.seq_len:
return
for i in range(len(data) - 1):
yield [data[i], data[i + 1]]
def generate_text(self, max_length = 15):
context = deque()
output = list()
if len(self.lookup_dict) > 0:
self.__seed_me(rand_seed = len(self.lookup_dict))
# This puts the first word in the text the first place of predictive text
chain_head = [list(self.lookup_dict)[0]]
context.extend(chain_head)
if self.seq_len > 1:
while len(output) < (max_length - 1):
next_choices = self.lookup_dict[context[-1]]
if len(next_choices) > 0:
next_word = random.choice(next_choices)
context.append(next_word)
output.append(context.popleft())
else:
break
output.extend(list(context))
else:
while len(output) < (max_length - 1):
next_choices = [word[0] for word in self.most_common]
next_word = random.choice(next_choices)
output.append(next_word)
print("context: {}".format(context))
return ' '.join(output)
def get_most_common_ngrams(self, n = 5):
print("The most common {} {}-grams: {}".format(n, self.seq_len, self.most_common[:n]))
def get_lookup_dict(self, n = 10):
print("Lookup dict: (showing the former {} pairs only)\n{}".format(n, dict(itertools.islice(self.lookup_dict.items(), n))))
我們一樣引入上述的BBC新聞當作原始文本:
# Load news article as raw text
with open("bbc_news.txt", 'r') as f:
raw_news = f.read()
接著我們創造一個以 2-gram 設計的馬可夫鏈產生器物件:
my_markov = MarkovChain(sequence_length = 2, seeded = True)
my_markov.add_document(raw_news)
試著生成一個由20個單詞所組成的段落:
random_news = my_markov.generate_text(max_length = 20)
print(random_news)
段落生成結果:
有點不知所云?我們試著用 3-gram 來生成段落,這時候單詞數選擇50:
my_markov = MarkovChain(sequence_length = 3, seeded = True)
my_markov.add_document(raw_news)
random_news = my_markov.generate_text(max_length = 50)
print(random_news)
檢視一下生成的段落:
我們可以發現,利用統計文本中 n-gram models 生成的文本,雖然在局部看來和不論是在語意或文法上並不會太不自然,但是整體而言卻顯得有些彆扭、詞不達意。這變是 statistical approaches 的缺點,而今日的語言預測加入了類神經網絡,大大拉近了模型預測的結果與自然語言的差距,甚至連身為使用者的我們都常分辨不出真偽呢!
今日的介紹就到此告一段落,祝各位連假愉快,晚安!